Having the best website and the best content is possible.
What happens, however, if your technical SEO is messed up?
If this is the case, you will not be ranked.
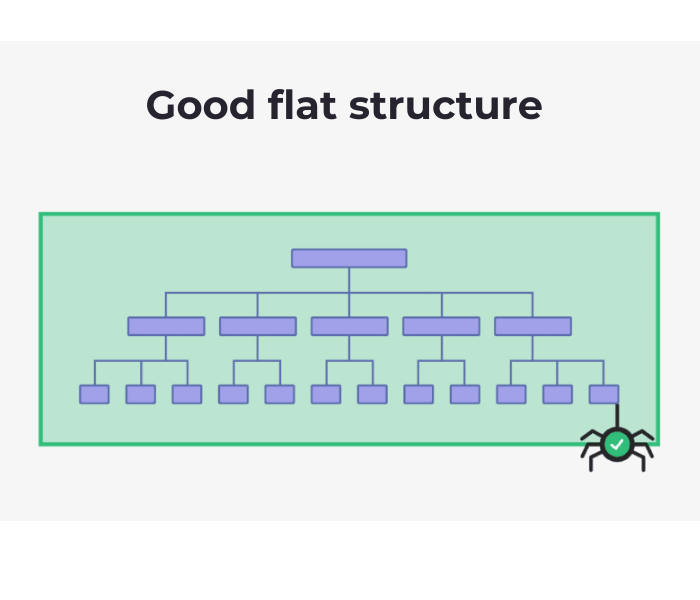
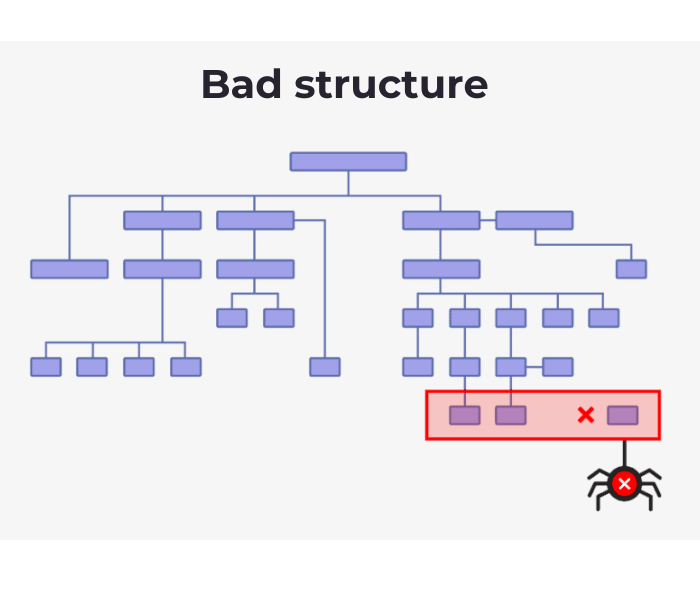
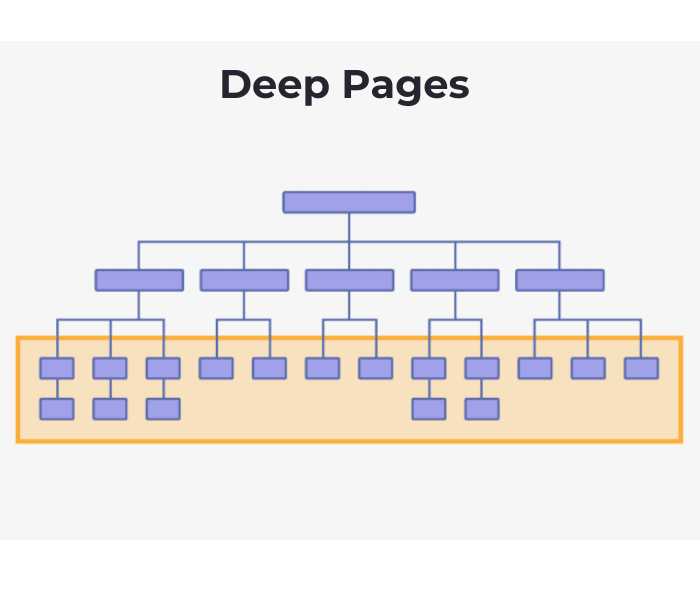
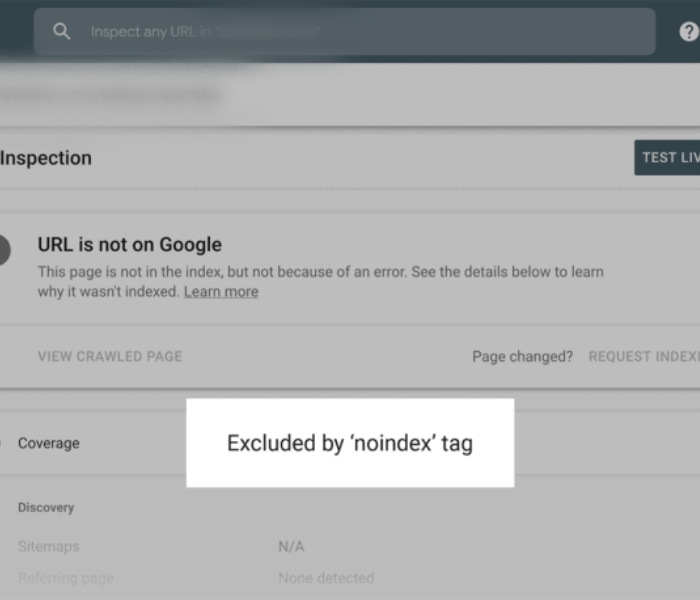
It is absolutely essential that Google and other search engines are able to find and crawl your website’s pages, as well as render and index the content on those pages.
Search engines must be able to find, crawl, render, and index the pages on your website in order for them to be useful.
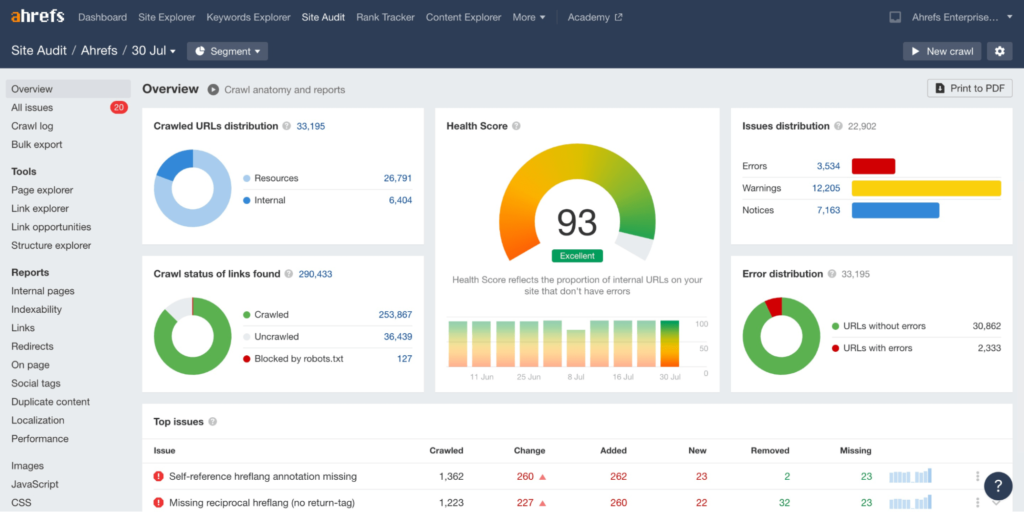
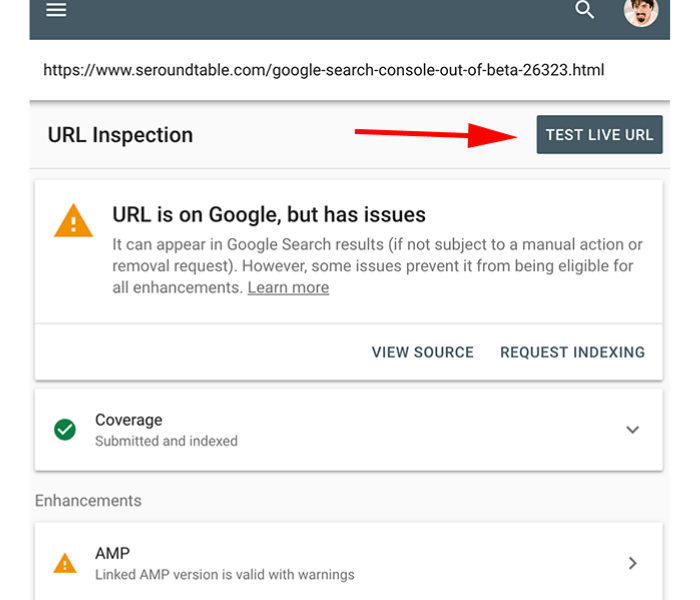
However, this is only the tip of the iceberg. Even if Google does index all of the content on your website, this does not imply that your work is finished.
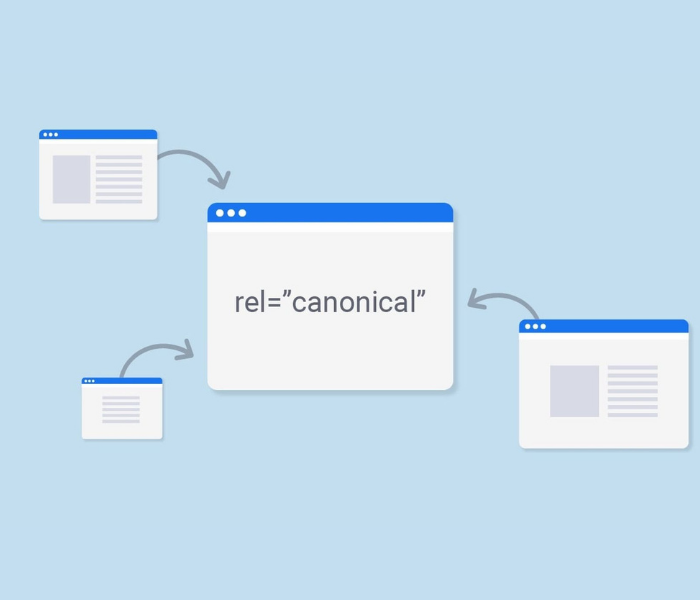
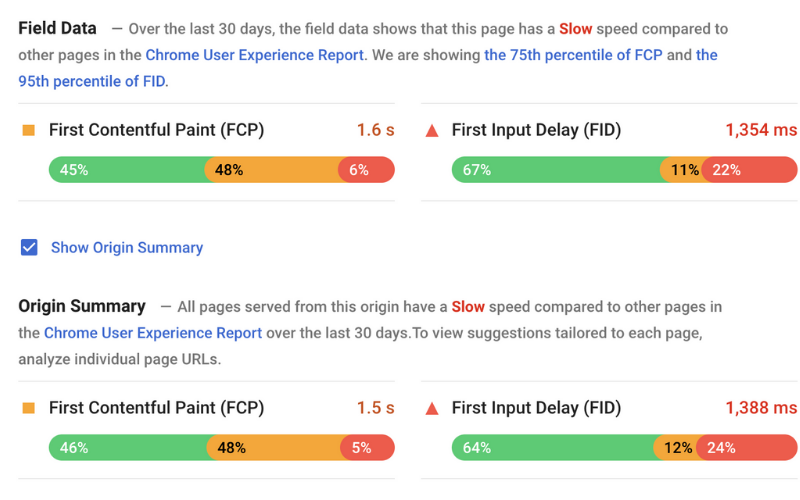
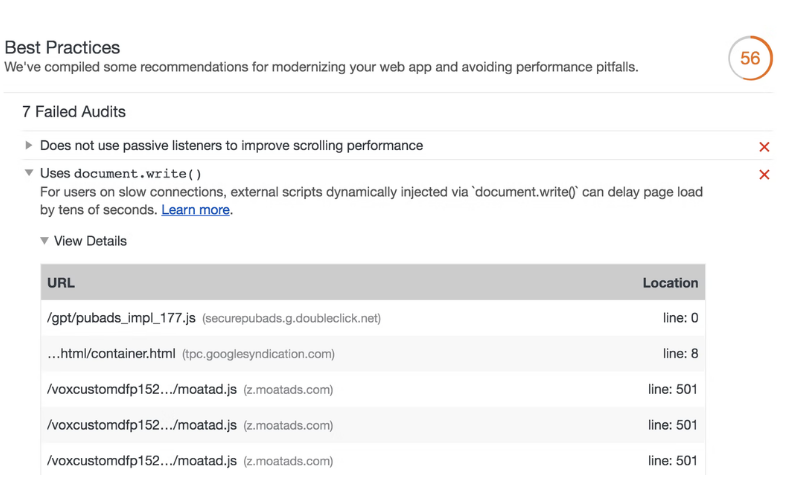
For example, in order for your site to be fully optimised for technical SEO, your site’s pages must be secure, mobile-friendly, free of duplicate content, fast-loading… and a thousand other factors that contribute to technical optimization.
That is not to say that your technical SEO must be flawless in order to rank well. It doesn’t work like that.
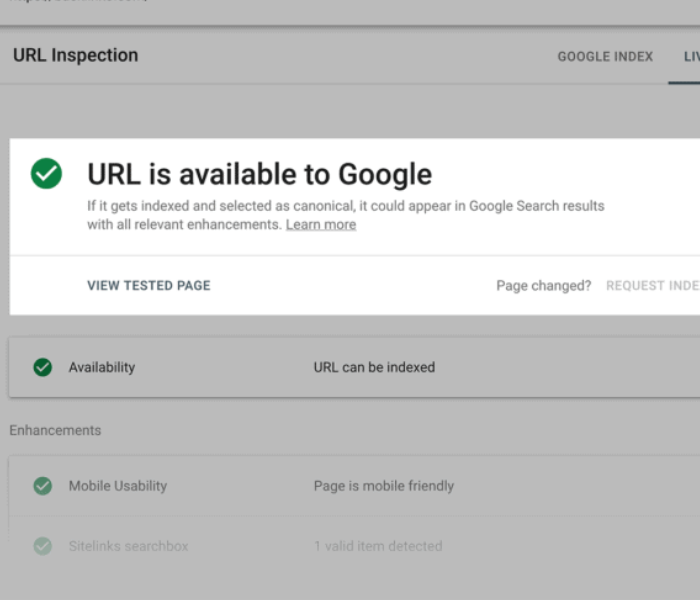
However, the more accessible your content is to Google, the better chance you have of ranking high in search results.